DP-600인증덤프샘플다운 - DP-600퍼펙트최신덤프
Wiki Article
Pass4Test DP-600 최신 PDF 버전 시험 문제집을 무료로 Google Drive에서 다운로드하세요: https://drive.google.com/open?id=15FYJ595AQHdJ6BRT_o2ZfbFbbLOHHEle
Pass4Test는 응시자에게 있어서 시간이 정말 소중하다는 것을 잘 알고 있으므로 Microsoft DP-600덤프를 자주 업데이트 하고, 오래 되고 더 이상 사용 하지 않는 문제들은 바로 삭제해버리며 새로운 최신 문제들을 추가 합니다. 이는 응시자가 확실하고도 빠르게Microsoft DP-600덤프를 마스터하고Microsoft DP-600시험을 패스할수 있도록 하는 또 하나의 보장입니다.
Microsoft DP-600 시험요강:
| 주제 | 소개 |
|---|---|
| 주제 1 |
|
| 주제 2 |
|
| 주제 3 |
|
최신버전 DP-600인증덤프샘플 다운 완벽한 덤프문제
Microsoft DP-600인증시험패스에는 많은 방법이 있습니다. 먼저 많은 시간을 투자하고 신경을 써서 전문적으로 과련 지식을 터득한다거나; 아니면 적은 시간투자와 적은 돈을 들여 Pass4Test의 인증시험덤프를 구매하는 방법 등이 있습니다.
최신 Microsoft Certified DP-600 무료샘플문제 (Q61-Q66):
질문 # 61
You need to ensure the data loading activities in the AnalyticsPOC workspace are executed in the appropriate sequence. The solution must meet the technical requirements.
What should you do?
- A. Create a pipeline that has dependencies between activities and schedule the pipeline.
- B. Create and schedule a Spark notebook.
- C. Create a dataflow that has multiple steps and schedule the dataflow.
- D. Create and schedule a Spark job definition.
정답:A
설명:
To meet the technical requirement that data loading activities must ensure the raw and cleansed data is updated completely before populating the dimensional model, you would need a mechanism that allows for ordered execution. A pipeline in Microsoft Fabric with dependencies set between activities can ensure that activities are executed in a specific sequence. Once set up, the pipeline can be scheduled to run at the required intervals (hourly or daily depending on the data source).
Topic 1, Litware. Inc.
Overview
Litware. Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment
litware has been using a Microsoft Power Bl tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Fabric Environment
Litware has data that must be analyzed as shown in the following table.
The Product data contains a single table and the following columns.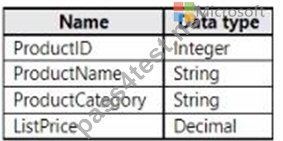
The customer satisfaction data contains the following tables:
* Survey
* Question
* Response
For each survey submitted, the following occurs:
* One row is added to the Survey table.
* One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Planned Changes
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Litware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity.
The following three workspaces will be created:
* AnalyticsPOC: Will contain the data store, semantic models, reports, pipelines, dataflows, and notebooks used to populate the data store
* DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate Onelake
* DataSciPOC: Will contain all the notebooks and reports created by the data scientists The following will be created in the AnalyticsPOC workspace:
* A data store (type to be decided)
* A custom semantic model
* A default semantic model
* Interactive reports
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers' discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements
The data store must support the following:
* Read access by using T-SQL or Python
* Semi-structured and unstructured data
* Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model.
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model.
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SQL queries and in the default semantic model. The following logic must be used:
* List prices that are less than or equal to 50 are in the low pricing group.
* List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
* List pnces that are greater than 1,000 are in the high pricing group.
Security Requirements
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC. Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
* Fabric administrators will be the workspace administrators.
* The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
* The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
* The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook.
* The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power Bl reports by using the semantic models created by the analytics engineers.
* The date dimension must be available to all users of the data store.
* The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
* FabricAdmins: Fabric administrators
* AnalyticsTeam: All the members of the analytics team
* DataAnalysts: The data analysts on the analytics team
* DataScientists: The data scientists on the analytics team
* Data Engineers: The data engineers on the analytics team
* Analytics Engineers: The analytics engineers on the analytics team
Report Requirements
The data analysis must create a customer satisfaction report that meets the following requirements:
* Enables a user to select a product to filter customer survey responses to only those who have purchased that product
* Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected date
* Shows data as soon as the data is updated in the data store
* Ensures that the report and the semantic model only contain data from the current and previous year
* Ensures that the report respects any table-level security specified in the source data store
* Minimizes the execution time of report queries
질문 # 62
You have a Fabric workspace named Workspace1 that contains a data flow named Dataflow1. Dataflow1 contains a query that returns the data shown in the following exhibit.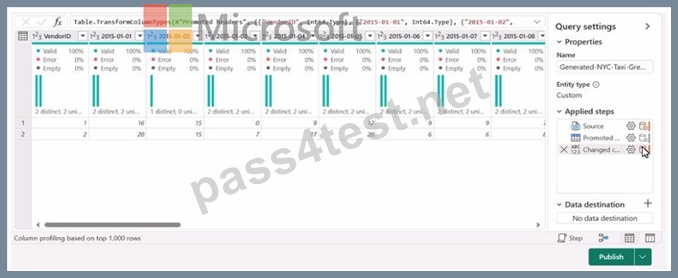
You need to transform the date columns into attribute-value pairs, where columns become rows.
You select the VendorlD column.
Which transformation should you select from the context menu of the VendorlD column?
- A. Group by
- B. Unpivot other columns
- C. Remove other columns
- D. Split column
- E. Unpivot columns
정답:E
설명:
The transformation you should select from the context menu of the VendorID column to transform the date columns into attribute-value pairs, where columns become rows, is Unpivot columns (B). This transformation will turn the selected columns into rows with two new columns, one for the attribute (the original column names) and one for the value (the data from the cells). References = Techniques for unpivoting columns are covered in the Power Query documentation, which explains how to use the transformation in data modeling.
질문 # 63
You have a Fabric tenant that contains a Microsoft Power Bl report named Report 1. Report1 includes a Python visual. Data displayed by the visual is grouped automatically and duplicate rows are NOT displayed. You need all rows to appear in the visual. What should you do?
- A. Reference the columns in the Python code by index.
- B. Add a unique field to each row.
- C. Modify the Sort Column By property for all columns.
- D. Modify the Summarize By property for all columns.
정답:A
설명:
To ensure all rows appear in the Python visual within a Power BI report, option C, adding a unique field to each row, is the correct solution. This will prevent automatic grouping by unique values and allow for all instances of data to be represented in the visual. Reference = For more on Power BI Python visuals and how they handle data, please refer to the Power BI documentation.
질문 # 64
You have a Fabric workspace that contains a complex semantic model for a Microsoft Power BI report. You need to optimize the semantic model for analytical queries and use denormalization to reduce the model complexity and the number of joins between tables.
Which tables should you denormalize?
- A. dimension tables on the same level of granularity
- B. role-playing dimension tables
- C. Snowflaked dimension tables
- D. fact tables on the same level of granularity
정답:C
질문 # 65
You are developing a complex semantic model that contains more than 20 date columns. You need to conform the date format for all the columns as quickly as possible. What should you use?
- A. ALM Toolkit
- B. DAX Studio
- C. VertiPaq Analyzer
- D. Tabular Editor
정답:D
질문 # 66
......
Pass4Test에서는 소프트웨어버전과 PDF버전 두가지버전으로 덤프를 제공해드립니다.PDF버전은 구매사이트에서 무료샘플을 다움받아 체험가능합니다. 소프트웨어버전은실력테스트용으로 PDF버전공부후 보조용으로 사용가능합니다. Microsoft 인증DP-600덤프 무료샘플을 다운받아 체험해보세요.
DP-600퍼펙트 최신 덤프: https://www.pass4test.net/DP-600.html
- DP-600시험대비 최신버전 덤프샘플 ???? DP-600시험덤프샘플 ???? DP-600최신버전 시험덤프공부 ???? ⮆ www.koreadumps.com ⮄을(를) 열고▶ DP-600 ◀를 검색하여 시험 자료를 무료로 다운로드하십시오DP-600최신 업데이트버전 공부문제
- DP-600인증자료 ???? DP-600시험대비 최신버전 덤프샘플 ???? DP-600인증자료 ???? ➡ www.itdumpskr.com ️⬅️에서 검색만 하면➡ DP-600 ️⬅️를 무료로 다운로드할 수 있습니다DP-600시험패스 가능 덤프문제
- 완벽한 DP-600인증덤프샘플 다운 덤프로 시험패스는 한방에 가능 ???? ▶ www.koreadumps.com ◀을(를) 열고✔ DP-600 ️✔️를 입력하고 무료 다운로드를 받으십시오DP-600인기문제모음
- 시험준비에 가장 좋은 DP-600인증덤프샘플 다운 최신버전 덤프자료 ???? 무료 다운로드를 위해 지금✔ www.itdumpskr.com ️✔️에서( DP-600 )검색DP-600최신버전 인기 시험자료
- 최신 업데이트버전 DP-600인증덤프샘플 다운 인증덤프 ???? ➥ www.pass4test.net ????을 통해 쉽게⏩ DP-600 ⏪무료 다운로드 받기DP-600시험패스 인증공부자료
- DP-600인증덤프샘플 다운 시험준비에 가장 좋은 인기시험 덤프 데모문제 ???? { www.itdumpskr.com }에서➤ DP-600 ⮘를 검색하고 무료로 다운로드하세요DP-600최신버전 인기 시험자료
- 높은 통과율 DP-600인증덤프샘플 다운 시험덤프로 시험패스가능 ???? 【 www.pass4test.net 】을(를) 열고「 DP-600 」를 입력하고 무료 다운로드를 받으십시오DP-600인기문제모음
- 최신 업데이트버전 DP-600인증덤프샘플 다운 인증덤프 ???? 검색만 하면▶ www.itdumpskr.com ◀에서➥ DP-600 ????무료 다운로드DP-600시험문제
- DP-600시험덤프샘플 ⛳ DP-600인증덤프 샘플문제 ???? DP-600인기문제모음 ✌ 지금⏩ www.dumptop.com ⏪에서▶ DP-600 ◀를 검색하고 무료로 다운로드하세요DP-600최신 덤프자료
- 높은 적중율을 자랑하는 DP-600인증덤프샘플 다운 덤프자료 ???? 시험 자료를 무료로 다운로드하려면「 www.itdumpskr.com 」을 통해✔ DP-600 ️✔️를 검색하십시오DP-600공부문제
- 높은 통과율 DP-600인증덤프샘플 다운 시험덤프로 시험패스가능 ☂ ⏩ DP-600 ⏪를 무료로 다운로드하려면➠ www.passtip.net ????웹사이트를 입력하세요DP-600최신 업데이트버전 공부문제
- liviahvmg702086.blogthisbiz.com, bookmarkrange.com, chiaraqxrd972928.vidublog.com, matteozqnn356231.wikihearsay.com, nikolasdree833223.dailyblogzz.com, idahchb115369.techionblog.com, janiceloyv972101.elbloglibre.com, bookmarkusers.com, nimmansocial.com, www.stes.tyc.edu.tw, Disposable vapes
Pass4Test DP-600 최신 PDF 버전 시험 문제집을 무료로 Google Drive에서 다운로드하세요: https://drive.google.com/open?id=15FYJ595AQHdJ6BRT_o2ZfbFbbLOHHEle
Report this wiki page